Events
Subscribe to Filter
Importing into Google Calendar
In the left-hand column of the Google Calendar main view, click the arrow to the right of "Other calendars" and click "Add by URL". In the form that appears, paste in the URL from the box above, and click the button to confirm.
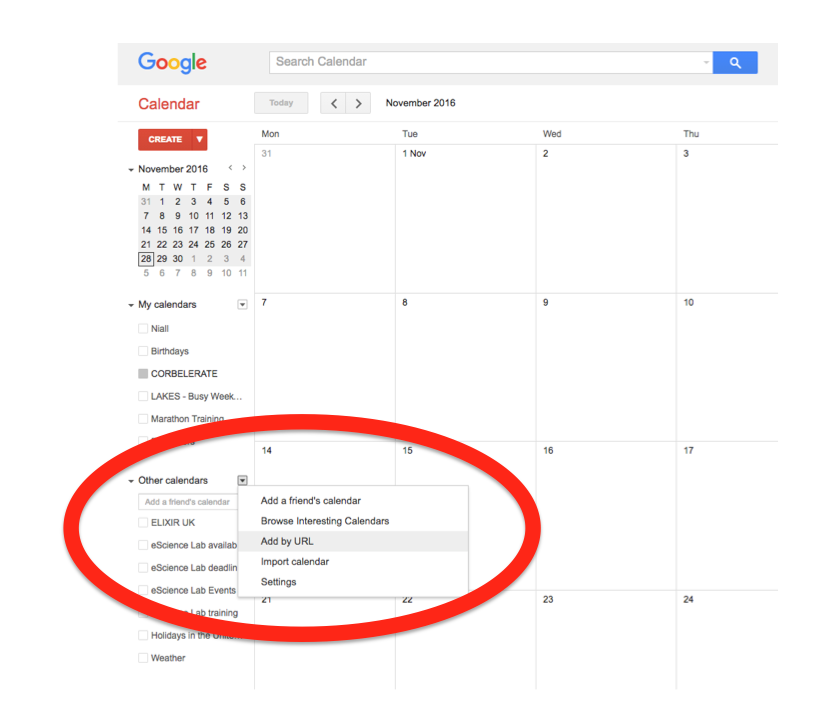
Please note, it may take a while for newly created events in TeSS to synchronise with your Google Calendar.
-
Meetings and conferencesWorkshops and courses
Using public data resources to build a business model

18 July 2018 @ 18:00 - 21:00
Cambridge, United Kingdom
Face-to-face
Bioinformatics Data integration and warehousing bioinformatics entrepeneurship data life sciences -
Workshops and courses
Workshop on Research Objects (RO2018)
29 October 2018 @ 09:00 - 17:00
Amsterdam, Netherlands
Face-to-face
Computer science Data management Data architecture, analysis and design Data integration and warehousing Data identity and mapping Data curation and archival Informatics Ontology and terminology Software engineering Workflows digital archives data repository linked data Workflows -
Workshops and courses
Introduction to multi-omics data integration
12 - 15 February 2019
United Kingdom
Face-to-face
Visualisation Omics Data integration and warehousing -
Meetings and conferences
Applied Bioinformatics in Life Sciences (3rd edition)
13 - 14 February 2020
Leuven, Belgium
Face-to-face
Machine learning Data integration and warehousing Bioinformatics Genomics bioinformatics genomics Proteomics Data Integration machine learning -
Workshops and courses
Systems biology: From large datasets to biological insight
21 - 25 June 2021
Online
Systems biology Machine learning Data integration and warehousing Systems (Systems) -
Workshops and courses
Applying mathematical modelling to biological problems in plant science
15 March 2023 @ 09:00 - 17:00
Online
Mathematical model Data integration and warehousing Plant webinar series Mathematical modelling plant science Data integration -
Workshops and courses
WEBINAR: BioSamples: supporting multi-omics data integration with FAIR sample records
4 October 2023 @ 16:00 - 17:00
Online
Data management Data integration and warehousing Omics Data curation and archival Data handling BioSamples Data Integration Metadata Multiomics Data submission Data curation
Note, this map only displays events that have geolocation information in
TeSS.
For the complete list of events in TeSS, click the list tab.